jq++ Design
This page describes the internal architecture of jq++, the tool that evaluates JSON++ configurations.
For the design principles behind JSON++, see the Design Principles page.
Evaluation Pipeline
jq++ transforms a JSON++ configuration file into plain JSON through a deterministic sequence of stages.
Each stage reads from the result of the previous one; no stage revisits earlier work.
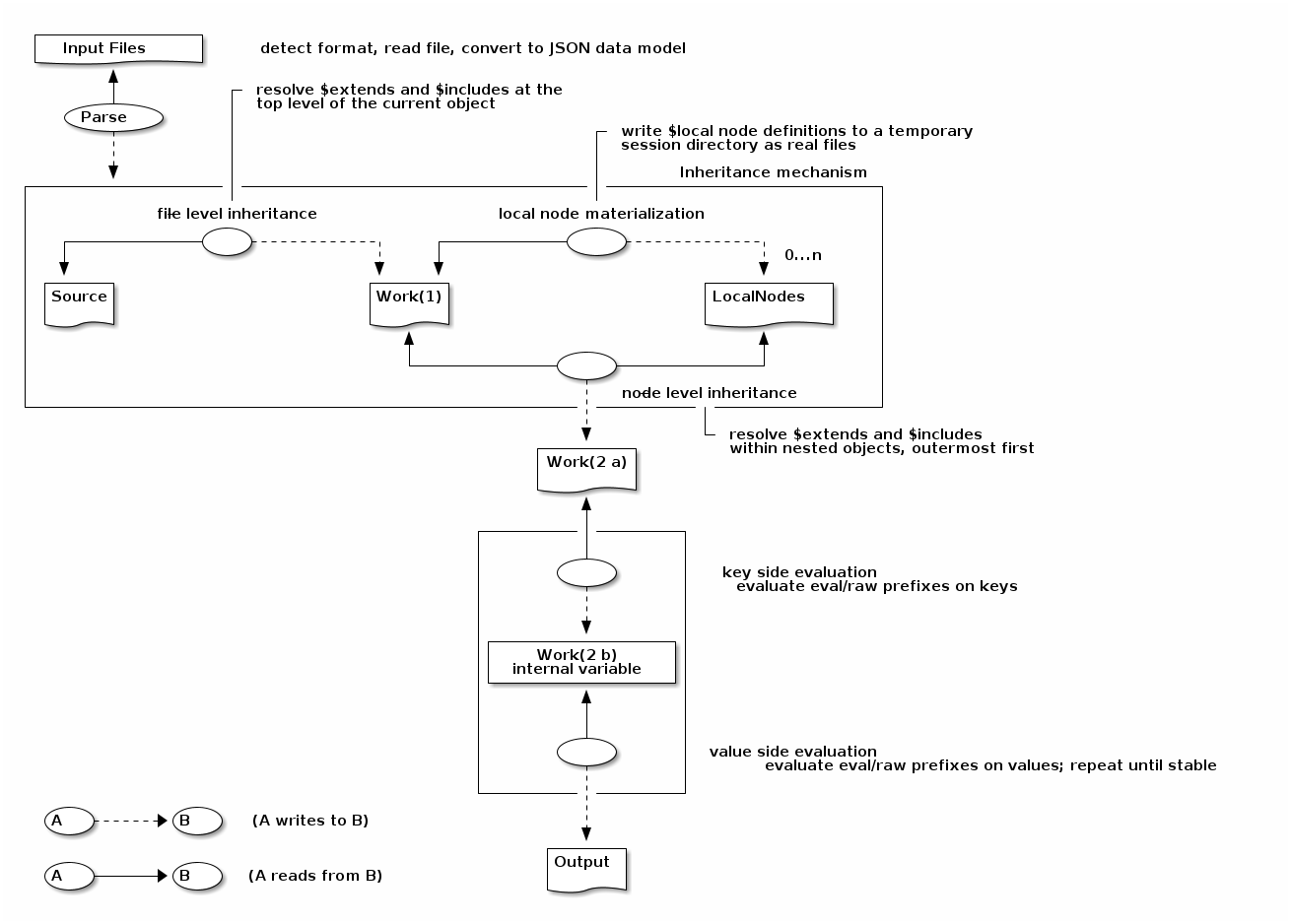
Each stage is described in detail below.
Stage 1 — Parse
The input file is read and converted to the JSON data model.
The file format is determined from the file extension.
YAML, TOML, JSON5, and HOCON files are decoded by their respective parsers and then normalised into the same map[string]any / []any representation used for JSON internally.
.jq files are a special case: they are parsed as jq source code and registered as a named jq module rather than as a data object.
The module name is the base filename without the extension.
Any eval: expression in a file that includes such a .jq file via $extends or $includes can call functions defined in that module.
Files with no extension or with .json++, .yaml++, .toml++, .json5++, .conf++, or .hocon++ are treated the same as their base format.
Stage 2 — File-level inheritance
$extends and $includes at the root of the current object are resolved.
Both directives are handled by the same underlying merge engine; the difference is in merge direction.
Resolving parents
For each filename listed in $extends or $includes, jq++ resolves the file against the search path (current file’s directory → local node search paths → JF_PATH), then recursively applies the full pipeline (stages 1–4) to that parent file.
The result is cached in a node pool so that each file is evaluated at most once per jq++ invocation, even when it is referenced from multiple places.
Circular inheritance chains are detected by tracking visited absolute paths. If a file that is already being resolved appears again in the chain, an error is reported immediately.
Merge semantics
mergeObjects(parent, child) combines two objects, with the child’s values taking precedence.
The merge is recursive for nested objects: if both parent and child have a key whose value is an object, those objects are merged recursively rather than the child object replacing the parent object wholesale.
For any other value type (string, number, boolean, array, null), the child value simply replaces the parent value.
Given $extends: [A, B], A is merged over B first, then the current object is merged over that result, giving the priority order: current object → A → B.
Given $includes: [A, B], B is merged over the current-plus-extends result, then A is merged over that, giving the opposite priority order: B → A → current object.
In other words, $includes fragments override everything that $extends and the current object establish.
Processing order
$extends is always resolved before $includes, so that $includes can override the combined result.
Stage 3 — Materialize local nodes
Objects defined under the $local key are extracted and written as individual files in a temporary session directory that is created fresh for each top-level jq++ invocation.
Each local node name becomes its own file (e.g. BaseThing becomes a file BaseThing with no extension, treated as JSON).
The session directory is placed on the front of the search path for the duration of processing.
This is what allows local node names to be used in $extends and $includes by bare name: they resolve against the session directory first.
Local node scope is tied to the file that defined them—specifically to the object tree rooted at that file—so local nodes from a parent are visible inside nodes that extend that parent, but not from unrelated sibling nodes.
The $local key is removed from the object before further processing.
At the end of the invocation, the session directory is deleted.
Stage 4 — Node-level inheritance
After file-level inheritance is settled, the entire object is scanned for nested objects that themselves contain $extends or $includes keys.
These are resolved in outermost-first order: a node at depth 1 is processed before a node at depth 2 that might be contained within it.
The same merge engine, search path, caching, and circular-reference detection used in stage 3 apply here too. Node-level inheritance therefore has exactly the same semantics as file-level inheritance; only the scope differs.
Stage 5 — Key-side evaluation
All keys in the resolved object that start with eval: or raw: are processed.
-
A
raw:key has its prefix stripped and is renamed to the remainder. -
An
eval:key is evaluated as a jq expression. If the result is a string, the key is renamed to that string. If the result is an array of strings, the key is replicated once per element, with each copy of the value placed under its respective new key.
Key evaluation may produce new eval: or raw: keys.
The stage therefore runs in a loop, decrementing a time-to-live counter (starting at 7) on each pass, until no more such keys remain or the counter reaches zero (which causes a panic indicating a likely infinite loop in the configuration).
Stage 6 — Value-side evaluation
All string values in the object that start with eval: or raw: are evaluated.
-
A
raw:value has its prefix stripped; the remaining string is the final value. -
An
eval:value is compiled and executed as a jq expression against the current full object as input. The expression has access to the builtin variables$curand$curexpr, and to the JSON++ builtin functions (ref,refexpr,reftag,parent,parentof,topatharray,topathexpr,readfile).
An eval: result may itself be a string starting with eval: (for example, when a value is resolved via ref and the referenced value is also an expression).
The stage therefore loops, decrementing its own time-to-live counter (starting at 7) on each pass, re-evaluating until no eval: strings remain.
Circular references within expressions—where evaluating value A leads back to value A—are detected via a visited-path map that is threaded through the evaluation call chain, and reported as errors immediately.
Stage 7 — Output
The fully resolved map[string]any object is serialised to JSON with two-space indentation and written to standard output.
When multiple input files are provided on the command line, each is processed independently and its output is written in order.
When no file arguments are given, jq++ reads from standard input, writing the input to a temporary file first (since the inheritance resolution needs a filesystem path to anchor relative file references).
Node Pool and Caching
The node pool is the shared state that persists across all recursive inheritance resolutions within a single jq++ invocation.
Its two main responsibilities are:
Caching.
A NodeEntryKey (base directory + filename) maps to a NodeEntryValue (resolved object + accumulated jq modules).
The first time a file is requested, it is fully resolved through stages 1–4 and the result is stored.
Subsequent requests for the same file return the cached result directly, avoiding redundant work and ensuring consistent results when the same file is extended from multiple places.
Search path management.
The node pool maintains a stack of local node directories.
When a file is entered for processing, its session-local node directory is pushed onto the stack.
When processing returns from that file, the directory is popped.
The full search path at any point is: current file’s base directory + local node directory stack + JF_PATH entries.
Merge Object Semantics
mergeObjects(parent, child) performs a deep merge:
-
Keys present only in the parent appear in the result with their parent values.
-
Keys present only in the child appear in the result with their child values.
-
Keys present in both: if both values are objects, they are merged recursively using the same rule; otherwise the child value replaces the parent value entirely.
This means arrays are not merged—a child array replaces the parent array completely. Only nested objects receive the recursive treatment.